


风格迁移 AI 效果器 Comboulator 发布,另有一波 Google 和 Adobe 音乐 AI 新品袭来
经历了Sora带给大家的开年暴击之后,人工智能在音乐领域最近也有了新进展。
Google近期发布了一个颇具可玩性的音乐生成小产品MusicFX DJ[https://aitestkitchen.withgoogle.com/tools/music-fx],而Adobe也通过宣传视频展示了正在研究当中的Music GenAI Control[https://blog.adobe.com/en/publish/2024/02/28/adobe-research-audio-creation-editing]。 在大厂出品的产品之外,初创企业DataMind Audio带来了作为插件颇具潜力的Comboulator[https://datamindaudio.ai/]。
Datamind Audio 家的 Combobulator
DataMind Audio的Combobulator首先通过音乐人的已有音乐训练的神经网络,再将用户输入的音频经过神经网络的风格转移来重新合成不一样的音乐。这样,用户就能把自己创作的声音元素实时转换成另一位音乐人的独特风格。

图1:Combobulator
开发者表示,根据输入音频信号和神经网络中的信息合成新的音频的体验就像演奏乐器一样“演奏另一个音乐人的大脑“。 在音乐创作过程中,Combobulator的作用更像是一个效果插件,它将提供全新的音色,同时保留其节奏和旋律内容。
[https://www.youtube.com/watch?v=TJr9BY7HLdQ]
打开插件后可以选择要使用的神经网络或“音乐大脑”。该插件附送两颗“音乐大脑”,更多的选择则要通过DataMind的内建市场下载。每颗”音乐大脑“均由公司内部技术专家研发,销售额的50将支付给贡献数据的音乐家。DataMind的Ben Cantil解释道:“我们正在努力为音乐制作人建立一个新的商业模式,以便他们能通过根据其艺术风格进行训练的人工智能来赚取收入。”根据官网介绍,Combobulator的开发是依靠IRCAM推出的实时音频变分自动编码器RAVE框架[https://forum.ircam.fr/projects/detail/rave/]。
Combobulator插件界面中心是一个可视化区域,周围有两个滑块来控制幅度Scale和偏移Offset。增加幅度Scale会应用更广泛的新音色,从神经网络中提取更多信息;而减少幅度会逐渐使声音变得平静而单调。偏移Offset会改变神经网络中提取音色的位置。距离中心越远,声音结果与最初输出的音色就越不同。
插件还设有增益控制、三段均衡和瞬态控制器。宽度旋钮可将偏移Offset送入左右相反的声道,从而产生立体声宽度和分离感。还有一个调制部分,带有五个低频震荡LFO、五个包络跟随Envolope和MIDI输入。
Combobulator售价199美元,首发优惠价为129美元。
Comboulator在线使用地址:https://datamindaudio.ai/
[https://www.youtube.com/watch?v=k4pAxbuLxDc]
Google 家的 MusicFX DJ

图2:MusicFX DJ
Google于去年推出MusicLM改名为MusicFX,能够根据文本描述生成声音、音乐片段甚至整首歌曲(详见《Google 做了一个输入描述文字就可以自动生成歌曲的 AI》)。 人工智能可以理解与流派、情绪和乐器相关的提示,它可以模仿不同的音乐家的创作水平,并且生成适合特定场景(例如锻炼或学习)的音乐。
MusicFX最近加入了DJ模式,为平台添加了混音器风格的界面。当你输入多个提示词时,MusicFX DJ会将它们分层组合成一个乐曲,像DJ一样同步。你可以调整每个音乐层的重要程度,总共可以添加最多十个层次元素。下方的骰子图标将生成随机提示词,另一个随机按钮将随机化每层的级别。与MusicFX的常规版本不同,DJ模式没有导出下载的选项。
Google DeepMind的Adam Roberts本周在Twitter/X上分享了MusicFX DJ,并评论道:
“我喜欢现场音乐以及个人表达。这就是为什么我对“DJ模式”感到兴奋。这是一个由你控制的无限AI jam。
MusicFX DJ通过让你更好地控制多个音乐部分的混合和编辑将此类人工智能驱动的音乐生成器推向了DAW领域。诸如此类的进步预示着未来,人工智能驱动的音乐软件将能够生成旋律、和弦和音色、创建编曲、编辑采样、使用效果器,甚至完成混音和母带。所有这些都通过文本或语音指令完成。
在线使用 MusicFX:https://aitestkitchen.withgoogle.com/tools/music-fx
Adobe 家的 Project Music GenAI Control
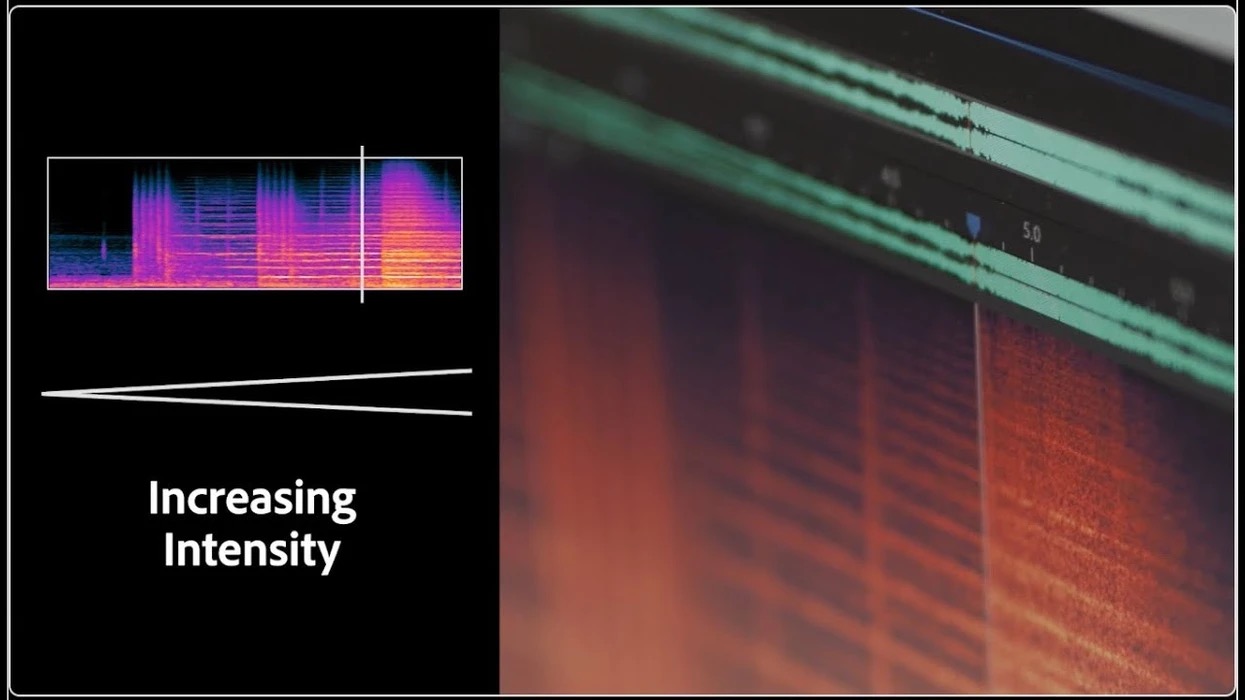
尽管Adobe以其图像和视频编辑工具而闻名,但它对音频领域并不陌生:Audition是后期制作人员的热门选择。一段时间以来,Adobe一直在逐步将人工智能集成到其产品中。它去年推出了在Photoshop中工作的AI图像生成器Firefly,以及一套网页AI音频编辑工具AI Audio Enhancer(请看《评测:用 Adobe AI Audio Enhancer 修复语音》)。
新发布的Project Music GenAI Control是一款人工智能音乐生成和编辑工具,它可以使用文本提示中的指令生成音乐,并允许进行细粒度的、基于人工智能的音频编辑。与Google的MusicFX和Meta的MusicGen(请看《深入揭发:Facebook 人工智能音乐模型 MusicGen 是如何通过参考旋律生成音乐的?》)非常相似,GenAI Control根据流派和情绪提示词来生成音乐片段。另外,用户可以通过人工智能实现匹配参考旋律、改变结构和节奏、增加和减少音乐强度和延长现有音乐长度。
Adobe Research高级研究科学家Nicholas Bryan解释道:
“这些新工具令人兴奋的是它们不仅仅是生成音频。它们为创作者提供了塑造、调整和编辑音频的能力,将其提升到Photoshop的水平。这是一种对音乐的像素级控制。”
[https://www.youtube.com/watch?v=J6jhWyU5lBY]
在视频中,GenAI Control为现有的旋律线生成了管弦乐伴奏,然后将整段音乐转变为嘻哈风格。之后又生成了一个ABA结构的R&B片段和“groovy rock”的loop。虽然视频中听到的音乐确实有点无趣,但GenAI Control仍处于早期开发阶段。产品发布时说不定会有惊喜。
Project Music GenAI Control在线使用:https://blog.adobe.com/en/publish/2024/02/28/adobe-research-audio-creation-editing
Tiktok
图3:
TikTok用户Jonah Manzano展示音乐生成功能[https://www.tiktok.com/@jonahcruzmanzano/video/7325235883303636226?lang=en]
另据TechCrunch报道,字节跳动旗下产品Tiktok近日测试了与MusicLM类似的文本提示音乐生成工具。目前该功能仅对一小部分用户开放。字节跳动此前发布的Ripple内也已具有部分音乐生成的功能。随着环球音乐集团与Tiktok的战火愈演愈烈,且环球音乐集团将限制人工智能音乐作为重点谈判内容,字节跳动在音乐人工智能上的动作将备受关注。
人工智能音乐产品大集合
最近几年来,人工智能音乐产品层出不穷。Baden-Württemberg流行音乐学院[https://www.popakademie.de/en/]将这些产品进行了整理。
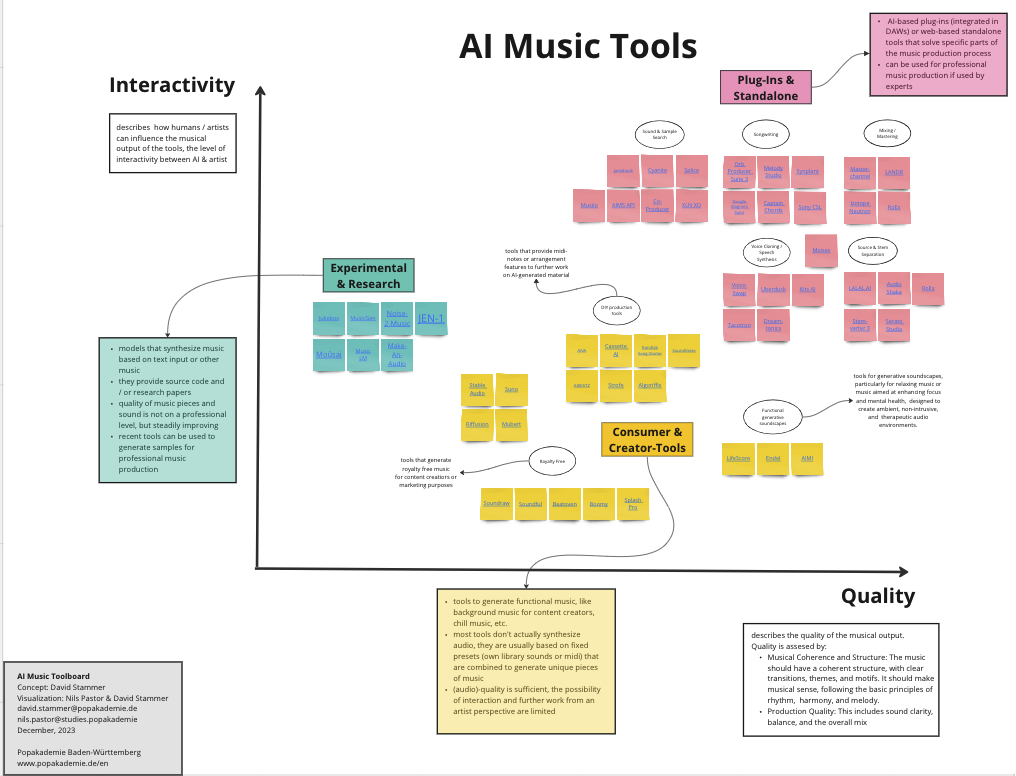
图4:图片分辨率有限无法全部展示,请访问以下链接查看大图:
https://miro.com/app/board/uXjVM8uA-30=/
上图根据质量和交互方式两个维度整理了人工智能音乐产品,并将其分为科研项目、消费创作工具和专业工具三大类。每一大类中还有更详细的分类和说明。
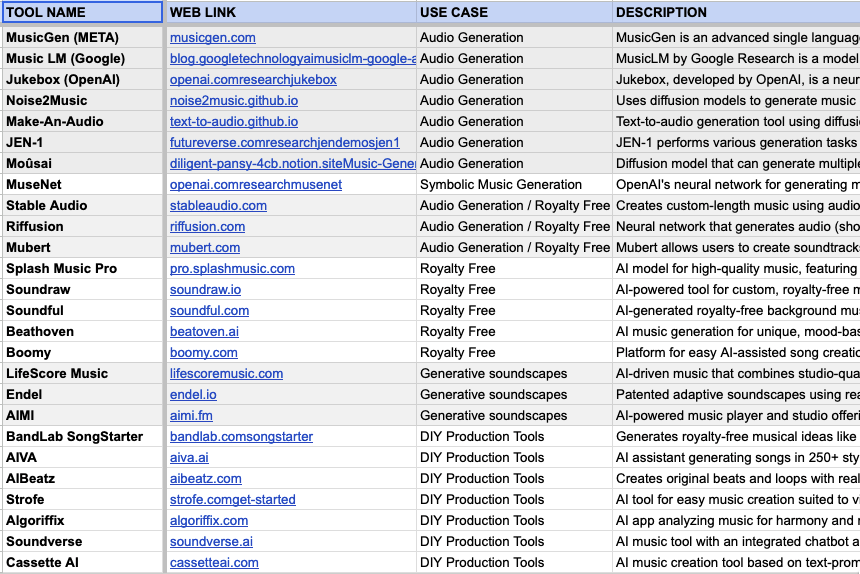
图5:图片分辨率有限无法全部展示,请访问以下链接查看在线表格:
https://docs.google.com/spreadsheets/d/1_rbSL_8EyeuX4BKmdiqk5G_4XhTEjoLBUfB69vLUbA0/
这个表格中,各人工智能产品按应用场景进行分类,并附有简要描述。值得注意的是,表格并未列出仅在中国运营的产品。另外,更多泛音频领域的人工智能项目也不在此列。
2024 年的人工智能音乐
2023年,我们见证了MusicLM开启文本提示词音频直接生成领域,引发各大科技企业和创业公司竞相加入竞争。不过音乐领域的进展仍然落后于语音、自然语言处理和计算机视觉领域至少1-3年。这一方面是由于各方面的技术不够成熟,与其他领域的研究投入相比缺乏资金、时间和研究人员。另一方面,音乐人工智能还未出现具有说服力的商业产品。在音乐人工智能的潜力得到公认之后,大批初创公司成立,但这些产品尚未大规模参与进音乐人的工作流程。长期观察该领域的博主Max Hilsdorf乐观地认为这两个方面都将在2024年得到改善,并对音乐人工智能的未来方向做出几点预测。
1. 可控且自然的音源分离
图6:
音源分离的第一个重大突破发生在2019年,当时Deezer发布了作为开源工具的Spleeter[https://github.com/deezer/spleeter]。大家熟悉的iZotope RX(参见《音频修复软件业界翘楚跨界再进化:iZotope RX 10 简测》)、Spectral Layers(详见《Steinberg 发布频谱编辑/修复软件 SpectraLayers 10 ,重建核心并加强 AI 辅助能力》)和Acoustica(详见《Acon Digital 发布 Acoustica 7.5,增加自动语音识别功能和新处理工具》)中都使用了Spleeter的技术。DJ产品Virtual DJ(详见《Virtual DJ 发布 2021 版本更新,加入实时音轨分离功能》)和djay PRO(详见《Windows 版 djay Pro 回炉重造,新版本也支持 AI 抽分轨了》)中的音源分离也是利用Spleeter作为基础。
自这次技术飞跃以来,该领域的进展趋于稳定。尽管如此,如果将原始版本的Spleeter与Meta的DEMUCS[https://github.com/facebookresearch/demucs]等现代开源工具或LALAL.ai(详见《福利:免费的在线音乐分离工具 LALAL.AI 发布升级,新增对乐器提取的支持》)等商业产品进行比较,效果必定是天壤之别。
音源分离是解决其他音乐人工智能问题的关键技术。快速、灵活、干净的音源分离可以将音乐分类、标记或训练数据增强等其他研究任务提升到一个新的水平。目前的音源分离技术在运算速度和灵活性上还有待提高。
音源分离通常在较大型的生成神经网络上运行。对于个别曲目来说,这可能没问题。然而,对于商业应用中遇到的较大工作负载,速度通常仍然太慢——尤其是没有显卡助力的情况下。在灵活性上,目前的音源分离还是基本局限于人声、鼓、贝斯和其他乐器共四种。根据用户需求定制的音源分离需要为此训练一个全新的神经网络。另外Max Hilsdorf认为音源分离速度足够快的话可以催生许多有趣的应用,例如黑盒音乐人工智能可解释化的问题[https://towardsdatascience.com/making-music-tagging-ai-explainable-through-source-separation-2d9493547a7e]。
2. 通用音乐嵌入General-Purpose Music Embeddings

图7:由DALL-E 3生成
为了了解什么是音乐嵌入,让我们看看这个术语的起源的自然语言处理领域。在嵌入出现之前,该领域主要依靠更简单的、基于统计的方法来理解文本。这种方法被嵌入embeddings的引入彻底改变。嵌入是单词的数学表示,其中单词之间的语义相似性反映在此嵌入空间中的向量距离。 简而言之,单词、句子或整本书的含义可以被分解为一堆数字。
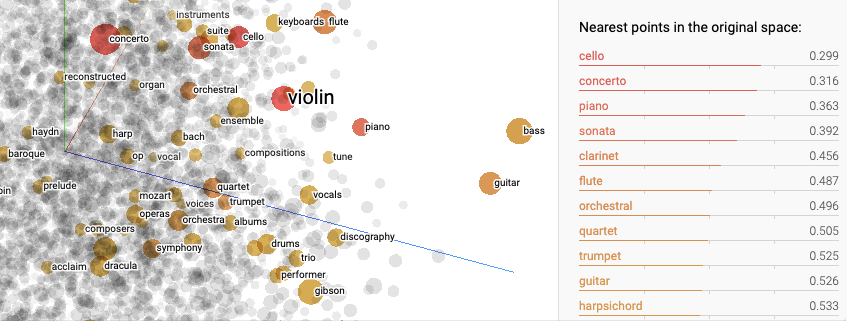
图8:在Tensorflow Embedding Projector[https://projector.tensorflow.org/]上使用 t-SNE可视化Word2Vec(10k) Embeddings。 与“violin”在嵌入空间距离最接近的的5 个术语分别是“cello”, “concerto”, “piano”, “sonata”和 “clarinet”。
ChatGPT等语言模型的成功已经验证了嵌入的实用性。只要有高质量的音乐嵌入,就可以以最少的开发工作立即实现:
- 音乐相似性搜索:在任何音乐数据库中搜索与给定参考曲目相似的音乐。
- 文本到音乐搜索:使用自然语言搜索音乐数据库,而不是使用预先定义的标签。
- 高效的机器学习:基于嵌入的模型所需的训练数据通常比基于频谱图或类似音频表示的传统方法少10-100 倍。
3.弥合技术与需求之间的差距

图9:由DALL-E 3生成
2023年对人工智能来说可谓难以定义的一年。一方面,人工智能已成为科技领域最大的流行语,几乎所有用户和企业都可以找到ChatGPT、Midjourney等产品的使用场景。另一方面,只有极少数产品被用户广泛接受。AI孙燕姿在网络上大行其道,但到目前为止,还没有围绕此类技术构建商业案例。从这个角度来看,音乐人工智能的最急需的突破可能不是一项花哨的研究创新。相反,我们需要不断成熟的人工智能的产品来满足企业或最终用户需求。
番外:训练数据侵权,Stable Audio研发主管辞职抗议
版权一直是包括文本、图像、音频在内的生成式人工智能所面对的一大难题。去年9月Stability AI发布的Stable Audio一时间引发了高度关注,之后却因版权问题引发内部动荡。Stable Audio与MusicLM类似,都通过文本提示生成音频音乐。关于Stable Audio的详细评测请见midifan的报道《深入揭发音乐人的噩梦 Stable Audio:音乐生成 AI 的商业技术背景 + 使用教程》。
在产品发布仅2个月后,负责开发Stable Audio的团队负责人Ed Newton-Rex宣布辞职,以抗议该公司在训练人工智能模型时使用受版权保护的材料。该事件得到BBC等主流媒体关注[https://www.bbc.com/news/technology-67446000]。

图10:Ed Newton-Rex接受BBC采访
Stability AI在产品发布时声称其使用来自AudioSparx内容库的音乐进行训练,而这些音乐是通过双方之间的数据访问协议获得的。Ed Newton-Rex在其Twitter/X帐户上对Stability AI的说法提出了质疑。Stability AI认为,根据“合理使用原则”,训练人工智能模型可以使用受版权保护的材料。Newton-Rex反驳道,美国法律规定,如果受版权保护材料的使用影响受版权保护作品的潜在市场,则“合理使用原则”不适用。

图11:
https://twitter.com/ednewtonrex/status/1724902327151452486
Newton-Rex是生成式人工智能的支持者,也是一名合唱作曲家,曾在剑桥大学取得音乐学士学位。他在其创立的人工智能音乐公司JukeDeck被字节跳动收购后曾在Tiktok人工智能部门任职,之后于2022年加入Stability AI。
Newton-Rex表示,Stability AI的训练不仅不受”合理使用“的保护,而且在道德上也是错误的。他说:
“价值数十亿美元的公司未经许可,在创作者的作品上训练生成人工智能模型,然后将其用于创建新内容与原创作品竞争。我不明白,这在一个已经建立了版权制度的和创意经济产业的社会里怎么能被允许。”
高管离职不是Stability AI面临的唯一难题,各方压力导致其面临自身难保的困境。据彭博社等媒体报道,总部位于纽约的Coatue对冲基金(持有Stability AI、字节跳动等公司股份)在10月份的一封信中表达了对该公司财务状况和领导力的担忧之后,就开始探索出售Stability AI的可能。Coatue敦促首席执行官Emad Mostaque辞职,理由是对他的管理风格感到不安,并且据称与高管离职风波有关。Midifan在此前的报道中就已提及Emad Mostaque的个人道德问题,包括编造学历和欺骗其他创始人等行径(详细报道请见品玩[https://www.pingwest.com/a/285687]和福布斯[https://www.forbes.com/sites/kenrickcai/2023/06/04/stable-diffusion-emad-mostaque-stability-ai-exaggeration/])。无论Stability AI今后的发展如何,在其版权问题得到解决之前,用户在使用Stable Audio生成的音乐时一定要多加留意,以避免未来不必要的法律纠纷。
本文参考链接:
- https://www.musicradar.com/news/datamind-audio-combobulator
- https://www.musicradar.com/news/google-musicfx-dj-daw
- https://www.musicradar.com/news/adobe-project-music-genai-control
- https://techcrunch.com/2024/01/19/tiktok-is-experimenting-with-a-feature-that-uses-ai-to-create-songs-based-on-prompts/
- https://musically.com/2023/12/19/music-ai-in-2023-a-database-of-tools/
- https://towardsdatascience.com/3-music-ai-breakthroughs-to-expect-in-2024-2d945ae6b5fd
- https://www.musicradar.com/news/stability-ai-training-copyright-resign
- https://www.digitalmusicnews.com/2023/11/30/stability-ai-sale-reports/#
转载新闻请注明出自 Midifan.com

相关资源
- Project Music GenAI Control 在线使用 2024-03-08
- MusicGen网址 2024-03-08
- 在线使用 MusicFX 2024-03-08
- Comboulator 在线使用地址 2024-03-08
Project Music GenAI Control 相关新闻
Comboulator 相关新闻
Google 相关新闻
- 让 AI 深度评价伍佰的《泪桥》:测试 Google Gemini 2.0「歌曲点评」功能
- Jacob Collier 与 Google 合作开发免费在线 AI 音乐创作工具 MusicFX DJ
- 风格迁移 AI 效果器 Comboulator 发布,另有一波 Google 和 Adobe 音乐 AI 新品袭来
- Google 做了一个输入描述文字就可以自动生成歌曲的 AI
- 现在你可以打开 Google 搜索来给乐器调音了
- Google 给你五台 AR Synth:利用增强现实技术将经典合成器带你的身边
- 人工智能 15 秒扒调:Google 推出的 Tone Transfer 能将任何音频转化为 4 种乐器
- Android Q beta 上线发布,内置原生 MIDI API 支持
- Google 竟然做了一款叫做 NSynth Super 合成器,而且还是基于机器学习的开源硬件
- Google Creative Lab 推出基于网页的 Song Maker 音序器游戏