


深入揭发音乐人的噩梦 Stable Audio:音乐生成 AI 的商业技术背景 + 使用教程
音乐人的噩梦最终还是来了,只需要输入简单的音乐感觉和风格提示词,Stable Audio就可以瞬间生成你需要的音乐,甚至是各种特殊音效。

自2021年横空出世,Stability AI一直被视作人工智能行业的第一梯队。他们最受欢迎的产品Stable Diffusion一直是Midjourney和 Dalle-2等其他图像生成模型的竞争对手。
2023年9月发布的Stable Audio[https://stability.ai/stable-audio]标志着Stability AI将触手伸向音乐领域,其音质似乎比同类文本音乐生成产品MusicGen和MusicLM高了一个台阶。数小时内,Stable Audio就获得了诸如Billboard、TechCrunch、VentureBeat和the Verge等主流媒体的报道。不到24小时,围观人群使网站服务器也达到了运行极限,不过在作者码字时,服务器已恢复正常运行。
Stable Audio的音乐生成模型使用的训练数据来自于制成音乐版权公司AudioSparx[http://www.audiosparx.com/]。Meta的同类产品MusicGen也是在与版权公司ShutterStock及其子公司Pond5达成协议后在其内容上进行模型训练的。在这种情况下,如果音乐人不希望他们的作品被用于训练Stable Audio的人工智能模型,AudioSparx提供了选择不参与的权利。 大约百分之10的音乐人选择退出。那些选择加入的人将从Stable Audio的收入中分得一部分。
请看Stable Audio生成音乐的介绍演示视频:
那么Stable Audio音乐生成的效果到底如何呢,我们听听看。
下面这段音乐使用的提示词是“氛围Techno、冥想、斯堪的纳维亚森林、808鼓机、808底鼓、拍手、沙筒、合成器、合成贝司、合成Drones、美丽、平和、空灵、自然、122拍每秒、器乐”(“Ambient Techno, meditation, Scandinavian Forest, 808 drum machine, 808 kick, claps, shaker, synthesizer, synth bass, Synth Drones, beautiful, peaceful, Ethereal, Natural, 122 BPM, Instrumental”)。
下面这段音乐的提示词是“Trance、伊维萨岛、海滩、太阳、凌晨 4 点、渐进、合成器、909、戏剧性和弦、合唱、欣快、怀旧、动态、流动”(“Trance, Ibiza, Beach, Sun, 4 AM, Progressive, Synthesizer, 909, Dramatic Chords, Choir, Euphoric, Nostalgic, Dynamic, Flowing”)。
Stable Audio不仅仅可以生成音乐,生成音效也不在话下。下面是两段音频,分别是汽车经过的声音和鼓独奏的片段。
我们再听一个。下面这组提示词是““迪斯科、驾驶、鼓、机器、合成器、贝斯、钢琴、吉他、器乐、夜店感、欣快、芝加哥、纽约、115拍每秒”(“Disco, Driving, Drum, Machine, Synthesizer, Bass, Piano, Guitars, Instrumental, Clubby, Euphoric, Chicago, New York, 115 BPM”)。
上面这个是Stable Audio的效果。为了对比,我们把同样的提示词扔到MusicLM的公测平台AI Test Kitchen中。MusicLM的结果也不差,不过音乐上更加重复。
Stable Audio最引人注目的进展是它在90秒的长度上保持的连贯性。其他人工智能模型也能生成几十秒的音乐,但通常在很短的时间(最多几秒钟)之后,它们就会演变成随机的、不和谐的噪音。Stable Audio的秘密在于前面提到的隐藏空间扩散结构,这种技术类似于Stable Diffusion用来生成图像的技术。Stable Audio的深度学习框架学习如何逐渐从几乎完全由噪音组成的音频中一步减去噪音,使其更接近文本描述。
Stable Audio并不是第一个基于扩散技术的音乐生成模型。2022年12月,我们报道了Riffusion,这是已知第一个对Stable Diffusion的音频生成的尝试,尽管在生成质量上与Stable Audio相去甚远。2023年1月,谷歌发布了MusicLM,其音频采样率为24kHz。现在,Stable Audio凭借44.1 kHz立体声的音质站到了领先位置。另外,Meta的MusicGen有更多功能,值得做一番比较。
Stable Audio和MusicGen都是人工智能文本控制音乐生成平台,但MusicGen包含根据现有音频进行可控生成和续写功能。用户可以将音频文件上传到MusicGen并通过提示词进行生成修改。MusicGen的几个应用场景,包括视频配乐、无限音乐生成以及音乐扩展。在这三者中,Stable Audio在可以配乐生成和无限音乐上竞争。不过根据已有音乐元素再加工是MusicGen独有的功能。MusicGen没有专用的用户界面,不便小白用户使用。体验MusicGen通常是使用Hugging Face和Google Colab等服务,根据使用的GPU数量按小时付费,当然有条件也可以在本地运行。总而言之,Stable Audio是一个对普通用户更友好的解决方案,但功能不及MusicGen。
上文提到过,AudioSparx提供了Stable Audio的训练数据,总共超过80万条音频,其中包含音乐、音效和单乐器演奏,以及相应的文本元数据和重要的文字描述。在将19500小时的音频输入模型完成训练之后,Stable Audio模型能够模仿生成它在提示词中对应的某些声音,因为这些声音已与其神经网络中的文本描述相关联。
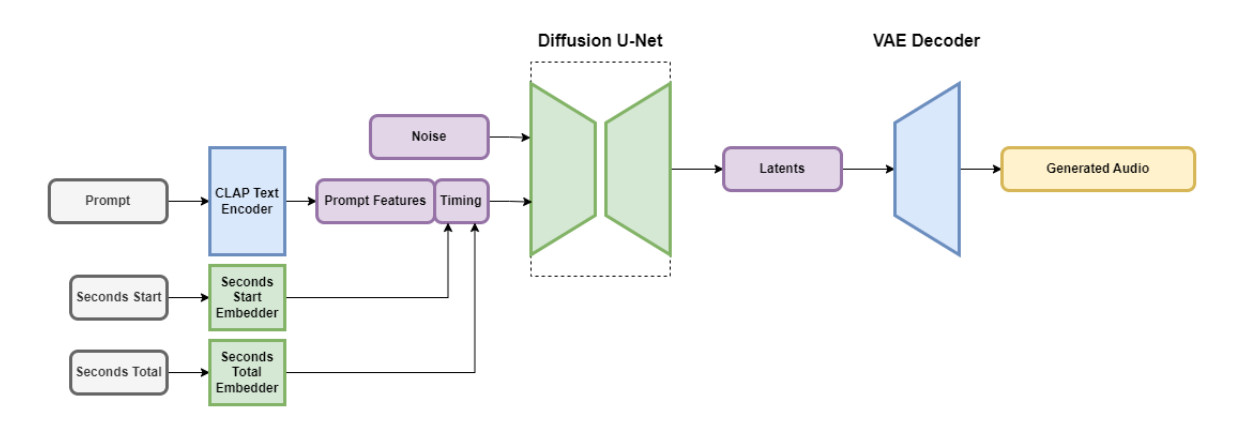
图2:Stable Audio模型架构
Stable Audio包含多个协同工作的组件,其中一部分组件以保留其重要特征的方式压缩音频,同时消除不必要的噪音。这使得模型的训练速度更快,推理生成的速度也更快。另一部分组件使用对应的文本来帮助指导生成音频的类型。
为了加快速度,Stable Audio在高度简化、压缩的抽象音频数据上运行以减少推理时间。根据Stability AI的说法,Stable Audio可以在Nvidia A100显卡上以不到一秒的运算时间渲染生成95秒的44.1 kHz采样率16位深立体声音频。虽然生成的音频在位深度和采样率这样的技术格式方面符合CD规范,但这并不意味着Stable Audio生成的音乐的实际听觉感知质量达到相应标准,尤其是考虑到其算法中数据高度压缩对音质的影响。
Stable Audio目前提供免费版本和每月12美元的专业版。免费用户每月最多可以生成 20首曲目,每首曲目的最大长度为20秒。专业用户允许每月生成500首曲目,长度最长可达90 秒。专业版本允许用户下载WAV文件并商用,而免费用户不得将音乐用于商业场景。另外,Stable Audio对更大规模的企业有特殊要求,使用Stable Audio的商业产品月活用户数超过10万,则需要联系协商Stability AI并获取更高级的许可。
接下来,我们通过教程一起学习Stable Audio的使用方法和一些小窍门。教程中还将总结Stable Audio的服务条款,以便了解如何安全合规使用其音乐。
使用教程
首先请进入Stable Audio网站[https://www.stableaudio.com/]。一旦完成注册并接受服务条款,你将到达如下界面。
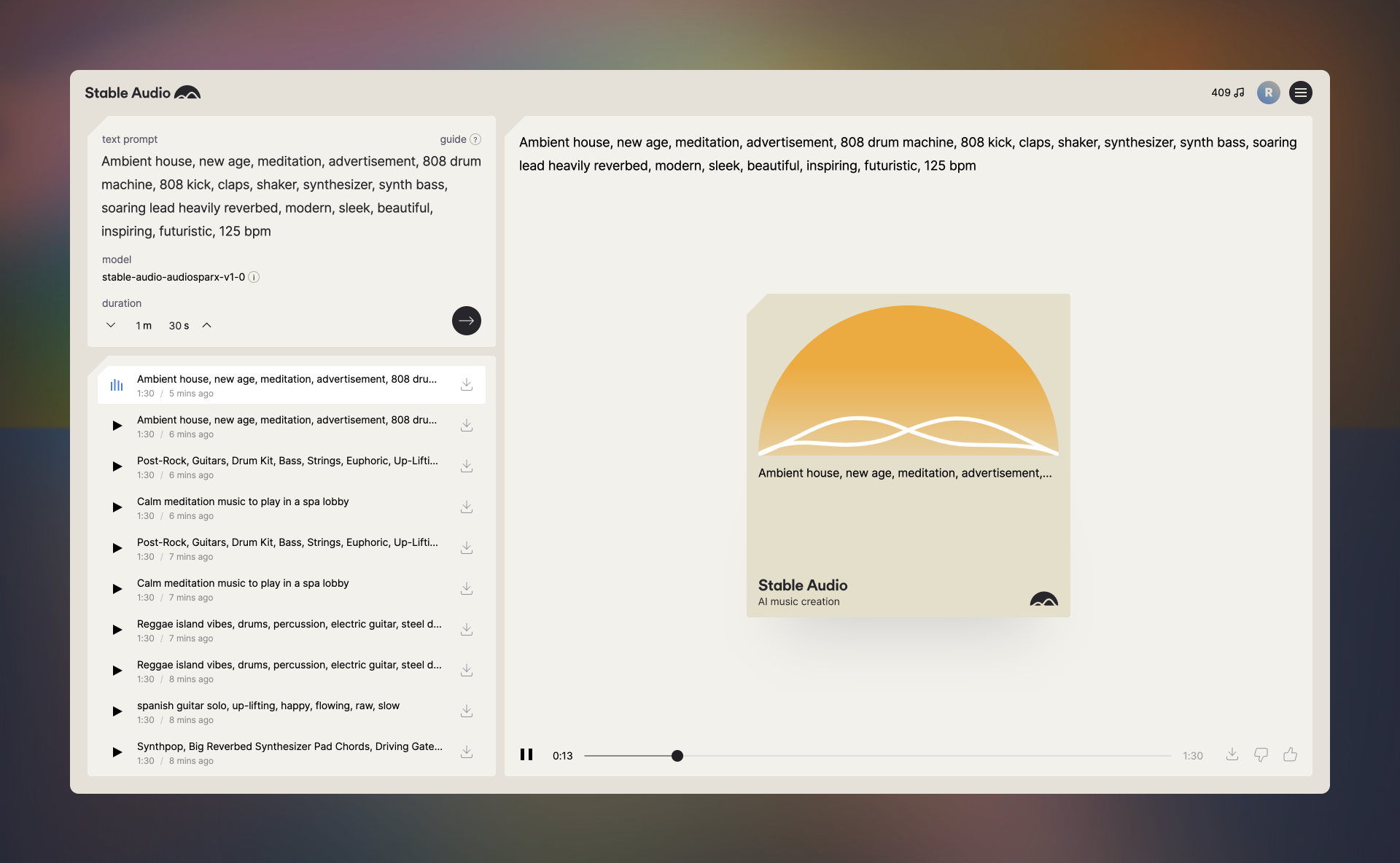
Stable Audio界面的左上边包含文本区域,你可以在其中输入音乐提示词。它还提供输出音乐时长的控制。每次提交文本提示时,左下角容器中都会出现一个新的列表项。同时,界面的右半部分显示播放控件,并让你可以选择下载曲目或对其质量进行投票。
现在,我们面临的问题是到底该在这个东西里写点什么。
Stable Audio的模型在 AudioSparx 上进行训练,所以当你使用与该数据集一致的词汇时,该模型的性能最佳。要找到训练数据中对应的文本,我们来到AudioSparx网站[http://www.audiosparx.com/]。
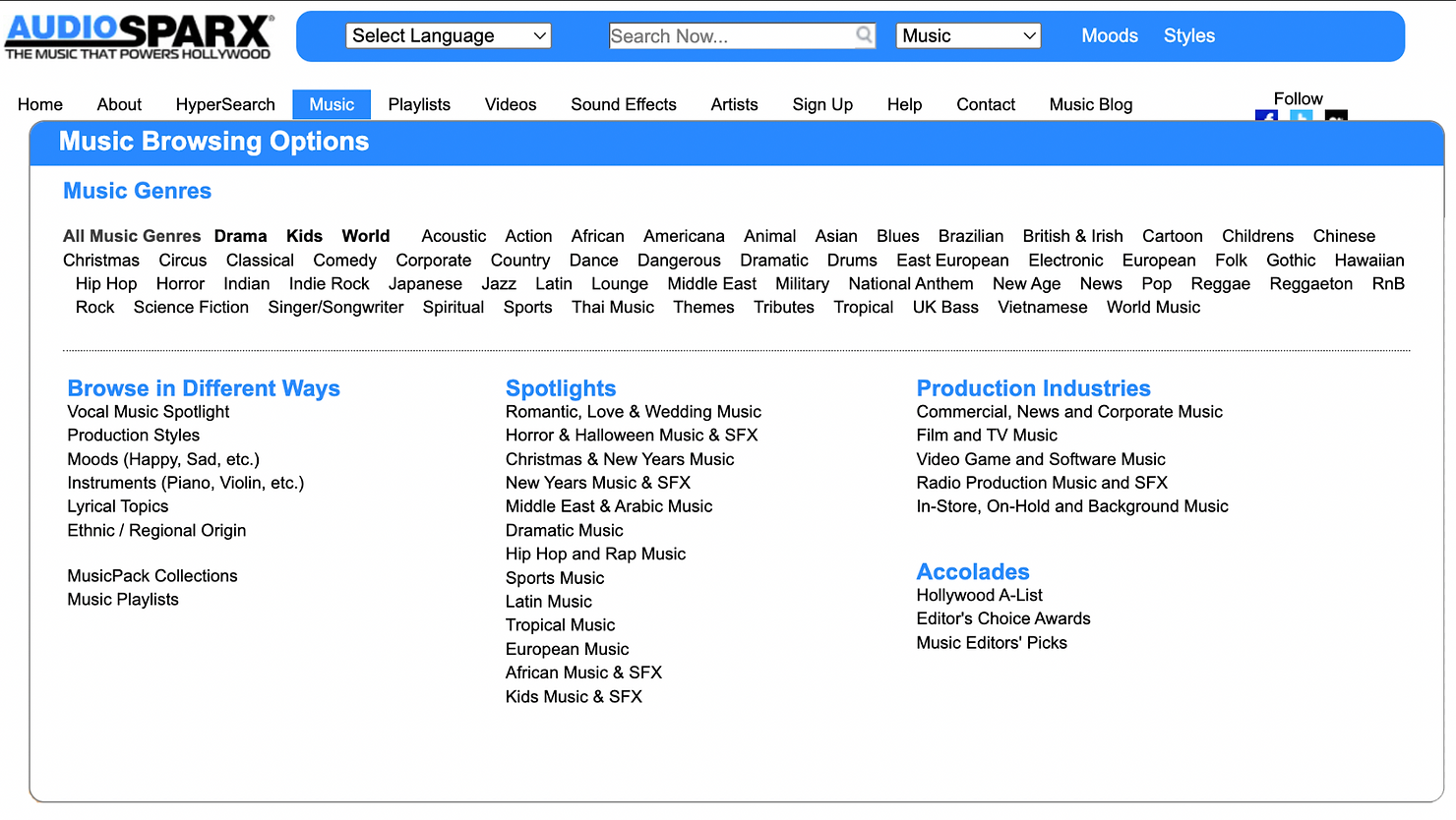
每个最高级别的音乐流派都链接到一个单独的页面,我们可以在其中找到相关子流派的列表。在下面的示例中,我们选择了电子音乐,并正在查看按字母顺序列出的前几个子流派。 每个集合中的曲目数量显示在标签的左侧。 具有更多曲目的子流派可能会为Stable Audio带来更丰富、更多样化的想法,以便在生成音乐时可以借鉴。单击子流派可查看其包含的完整音频文件集合。在每首曲目的标题下,您都会找到丰富的文本说明。尝试将描述性文本直接复制并粘贴到示例音频的提示字段中,看看会发生什么。调整文本并迭代多轮,直到您对其创建的音乐感到满意为止。
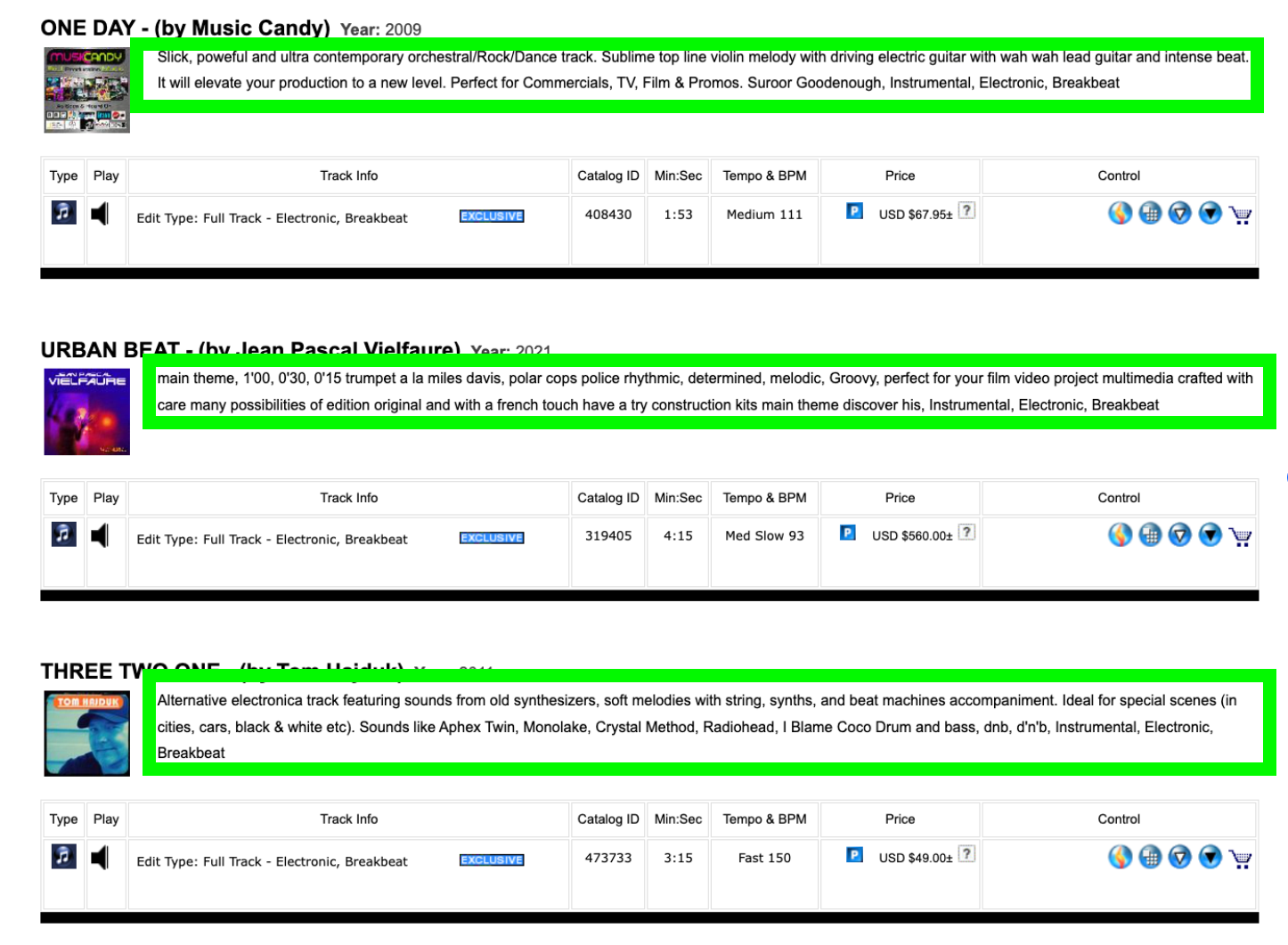
图5:AudioSparx中曲目的文字描述
使用包含音乐家姓名的描述时请务必小心。上图第三个示例的文字中包含Aphex Twin、Radiohead等名字。在后文中会讲到,Stable Audio的服务条款禁止滥用知识产权。我没有看到任何具体说明用户不能在提示词中提交音乐家姓名,但从字里行间看出,这是最明显的解释。这么理解吧,只要是为了自己的实验娱乐,你可以安全地尝试音乐家的名字。出于道德和法律原因,最好避免将以音乐家名字作为提示词生成的音乐用于商业用途。
Stability AI的研究科学家Jordi Pons本月发表了一篇文章[http://www.jordipons.me/on-prompting-stable-audio/],其中提供了一些Stable Audio使用的好技巧。下面就是对这些技巧的简单总结这些技术。
音乐提示词技巧#1:提供音乐属性列表
最简单的办法是从流派、乐器、情绪和节奏等描述词开始。
示例:低保真嘻哈、钢琴、贝斯、鼓、放松、90拍每秒(Lo-fi hip hop, piano, bass, drums, relaxing, chill, 90 BPM)。
音乐提示技巧#2:结合音乐和非音乐性描述
尝试添加非音乐性描述词,看看它如何融入音乐的感觉中。
例如:海岛歌曲、马林巴琴、站在海上、脚下有沙子、聆听海浪声、棕榈树在微风中摇曳的轻松体验 (Island song, marimba, the relaxing experience of standing on the ocean with sand beneath your feet, listening to the waves while palm trees sway in the breeze)。
完善提示词
如果你发现音乐输出听起来太数字化或电子化,Jordi建议在提示中添加“现场(Live)”或“乐队(Band)”等关键字。你可以通过输入“立体声(stereo)”、“高质量(high-quality)”和“44.1kHz”来提高音频质量。为了给旋律增添趣味,可以试试在曲目主乐器名称后添加“独奏(Solo)”一词进行配对。这些是文本提示的基本原则,但总有进一步实验的空间。 在下一节中,我们将分享一个新颖的示例。
Dadabots的CJ Carr多年来一直是Harmonai团队的一员,在音频合成方法上有些独特的见解。
上面的视频里CJ Carr演示了他的音乐流派融合技术。当你将两种不太可能的流派混在一起时会发生什么? 我们能否创造出世界上从未听过的全新音乐风格?

音乐流派融合提示词格式
此演示中的提示格式结合了两个短语,每个短语都以“Subgenre:”为前缀,并用竖线符号 (|) 分隔。
实验思路:尝试输入两种节奏相反的风格,例如“Subgenre:Breakbeat|Subgenre: Lo-fi Hip Hop”,或者牛头不对马嘴的两个流派,例如“Subgenre: Death Metal|Subgenre: New Age Relaxation”。在历史上的任何其他时期,像这样的流派融合都会被困在一种未被实践产生的潜在空间中。但现在,通过一些文本和一段时间的渲染,Stable Audio为我们完成了繁重的工作,并提供了新的创作想法。
流派扭曲是比我所说的音乐家混合更安全的替代方案。提示可以将“artist”一词替换为“subgenre”,并创建多个音乐家的混合体。但正如之前提到的,一旦我们开始将个别音乐家的品牌注入我们的提示中,我们就进入了法律的灰色地带。让我们仔细看看服务条款。
当我们注册新应用程序时,大多数人都会直接跳过条款和服务协议。但当谈到人工智能音乐生成时,对它们的条款有基本的认识是很重要的。以下是有关Stable Audio服务条款的一些最重要的信息:
- 音乐是你的:依照相关条款和法律,用户拥有他们生成的内容。
- 请勿使用稳定音频训练其他人工智能模型:禁止用户使用该服务或其生成的内容来训练其他人工智能模型。
- 尊重艺术家IP:用户不得侵犯知识产权。
- 如果你被起诉,你需要支付法律费用:用户应赔偿Stability因知识产权侵权、滥用服务或违反条款而引起的索赔。 Stability及其代表对间接、特殊或后果性损害或损失不承担责任。
衍生阅读:Stable Audio诞生背后的故事
对于任何关注人工智能音乐领域的人来说,Stable Audio的产品负责人都是一个熟悉的名字。Ed Newton-Rex是Jukedeck的联合创始人兼首席执行官,Jukedeck是最早的人工智能音乐初创公司之一,该公司于 2019 年被字节跳动收购。2021年离开字节跳动后,Newton-Rex在Snap旗下的音乐创作应用Voisey担任首席产品官一段时间。 随后,他于2022年11月加入 Stability AI,最初担任其专注于音乐的Harmonai项目的产品副总裁。今年2月,Newton-Rex调任音频副总裁,负责Stable Audio方面的工作。
一年前,总部位于伦敦的初创公司Stability AI悄悄发布了Dance Diffusion,该模型可以根据有关歌曲和音效的文本描述生成歌曲和音效。Dance Diffusion是Stability AI首次涉足生成音频领域,它标志着该公司对AI音乐创作工具这一新兴领域的投资和兴趣。 但在Dance Diffusion宣布近一年后,生成音频领域似乎一切都很平静——至少就Stability的努力而言是这样。
Stability资助创建该模型的研究组织Harmonai去年某个时候停止了Dance Diffusion的更新。从历史上看,Stability向外部团体提供资源和计算,而不是完全在内部进行研发。Dance Diffusion从未获得过面向用户的版本发布。即使在今天,安装Dance Diffusion也需要直接使用源代码,因为它根本没有用户界面。Stable Audio不是由单独开发Harmonai开发的。Stability 的音频团队于2023年4月正式成立,他们创建了一个受Dance Diffusion 启发的新模型来支持Stable Audio。
现在,在投资者要求将超过1亿美元的投入转化为创收产品的压力下,Stability AI重新大力投入音频领域。Stability AI声称该工具是第一个能够通过扩散模型技术生成用于商业用途的“高质量”44.1 kHz音乐的工具。Stability AI表示,经过音频元数据以及音频文件的持续时间和开始时间的训练,Audio Diffusion的底层大约12 亿个参数模型比之前发布的生成音乐工具能够更好地控制合成音频的内容和长度。Stability AI音频副总裁 Ed Newton-Rex在接受 TechCrunch电邮采访时表示:“Stability AI的使命是通过跨内容类型或模式构建人工智能模型来释放人类潜力。从Stable Diffusion开始,现已发展到包括语言、代码和现在的音乐。Stability AI相信生成人工智能的未来是多模态的。”
至少目前,也许从今以后,Stable Audio只能通过网页使用。Stability AI尚未正式宣布以开源方式发布Stable Audio背后模型的计划,此举肯定会惹恼其开放研究使命的支持者。
据 Newton-Rex称,他们采取了一些措施来过滤训练数据,大概是为了解决深度伪造声音潜在的道德和版权问题有点令人惊讶的是,Stability AI并没有过滤掉可能使其成为法律瞄准目标的提示。 如果输入“按照 Barry Manilow的风格”之类的内容,像 Google MusicLM这样的工具会抛出错误消息,但 Stable Audio不会——至少现在不会。当被问及是否有人可以使用Stable Audio来生成 Harry Styles或 The Eagles等乐队风格的歌曲时,Newton-Rex表示,该工具受到训练数据中音乐的限制,其中不包括一线艺人的音乐标签。也许是这样。但粗略搜索AudioSparx的库会发现数千首歌曲本来就是模仿披头士乐队、AC/DC等音乐“风格”的。
Newton-Rex说:
“Stable Audio的主要是为了生成器乐,因此信息造假和声音深度伪造不太可能成为问题,不过,我们正在积极努力应对人工智能中出现的风险,方法是在我们的模型中实施内容真实性验证标准和水印,以便用户和平台可以识别通过我们的托管服务生成的人工智能辅助内容。”
Stability与AudioSparx 的协议涵盖两家公司之间的收入分享,但Stability并未透露该交易的细节,也没有透露音乐人的贡献预计将获得多少报酬。鉴于Stability首席执行官埃马德·莫斯塔克 (Emad Mostaque) 的行为道德问题[https://www.pingwest.com/a/285687],音乐人有理由保持警惕。
- 参考原文链接1:https://www.audiocipher.com/post/stable-audio-ai
- 参考原文链接2:https://techcrunch.com/2023/09/13/stability-ai-gunning-for-a-hit-launches-an-ai-powered-music-generator/
- 参考原文链接3:https://arstechnica.com/information-technology/2023/09/ai-can-now-generate-cd-quality-music-from-text-and-its-only-getting-better/
- 参考原文链接4:https://musically.com/2023/09/13/stable-diffusion-maker-launches-stable-audio-text-to-music-ai/
文章出处 https://www.audiocipher.com/post/stable-audio-ai
转载新闻请注明出自 Midifan.com
-
2023-09-18
 匿名
试了一下,太差了,很呆板,音质低得想哭。
匿名
试了一下,太差了,很呆板,音质低得想哭。 -
2023-09-18
匿名
我试了一下,结果不太满意,比较呆傻,音质也很差。
