




VR 音频探秘之三:Spatial Audio 的实现方式
首先我们要明确的是,在Spatial Audio这个音频环境下,从前我们所熟知的Stereo、Surround这些音频模式都不存在了。在制作过程中取而代之的是声源和声场这两个概念。下面让我们从这两个概念出发,看一看Spatial Audio是如何实现的。
声源
- 使用HRTF技术去实现声源3D的方位感
每一个发声的物体,都可以看做是一个声源。我们可以用传统的方式去录制一个mono的声源,并在后期时运用3D panner工具,将这些声源定位在我们需要的虚拟3D空间中。也就是说,这是一种基于对象的(Object-Based)3D方式。那么这些3D Panner工具是如何将一个mono的声源定位到虚拟空间中的呢?当然是通过HRTF技术。让我们来看看HRTF信息是如何应用在3D Panner上的。
首先我们需要采集HRTF信息。在消声室中搭建一个球形扬声器阵列,在球形阵列的中央,将一对微型麦克风放置在一个人的外耳道口(或使用测试用仿真头话筒),然后从各个方向播放声音,分别录制下来。录制下的这些文件叫做HRIR(头部相关冲击响应),通过不同方向的HRIR与原始播放音频的对比,我们就可以得到不同方向HRTF。简单来说HRTF就是我们听到的声音与声源发出的声音之间的差异。

在3D Panner工具中,可以通过时域卷积或者快速傅里叶变换的方式,将HRTF信息加载到我们需要处理的声源音频上。就可以模拟出这个点声源定位在虚拟三维空间中的效果。这种方式为我们的音频制作带来什么样好处呢?首先,你不需要用仿真头去录音了,只要使用普通录音方式去录制一个单声道的文件就可以,也就是说你庞大的音效库仍然可以使用在Spatial Audio中。其次,你依旧可以随意使用你喜欢的各类效果器,只要这些效果器都在3D Panner之前就没问题。关于这类3D Panner我们会在后面进行介绍。
- 使用Sound Ray-Tracing+HRTF去实现声源3D的空间感
在上一篇的内容中,我们已经提到了3D这种属性不仅仅存在于声音的方位感,同样也存在于声音的空间感之中。我们现在通常使用的Reverb效果器,无论是立体声还是5.1都只能提供一个平面的空间感。那么如何去让一个声音的空间感也拥有3D的效果呢?使用过声学设计软件EASE的朋友们会知道,当我们完成了一个空间的建模,我们就可以通过声线跟踪(Sound Ray-Tracing)技术去计算这个空间内的冲击响应(IR),进而去模拟一个声音在这个环境中的空间感。并且我们还可以在试听模块中,加载HRTF信息去尽可能真实的模拟出人们在这个声学环境中的听觉感受。
所谓声线跟踪,就是从声源发出声音开始去模拟声音的传播的轨迹、在空间中的反射和扩散。当然也可以模拟出反射声的方向,再通过加载HRTF信息,我们就可以得到一种3D的空间感。现在,我们可以将这种技术应用到Spatial Audio当中,只不过受到运算量的限制,我们只能在这里使用一个最简单的房间模型,一个长方体的空间,通常也称为“ShoeBox Model”。 它只能通过调整房间的大小和墙边的材质去尽可能的模拟出我们想要的空间感,虽然很简单,但却能够为我们提供一个最基本的3D的空间感。目前NVIDIA的VRWorks Audio技术和AMD的TrueAudio Next技术都是通过这种声线追踪的方式,希望使用GPU运算为我们提供一个更好的3D空间感。

声场
声场是一个空间内所有声音的集合,是许许多多声源发出的声音在三维空间中传播,经过反射、衍射等一系列声学作用后形成的复杂声音。录制声场的技术,在现行的VR音频领域有两种方式Quad Binaural和Ambisonic。这也是被各类3D Panner插件所支持的两种格式。
- Quad Binaural
了解了前面的内容,我们现在就很容易去理解Quad Binaural了,即将其简单的理解为一个4向的仿真头话筒,我们可以通过它获得0°、90°、180°、270°这四个水平方向的带有HRFT信息的声场。当然,如果声音来自这四个方向以外的角度,比如120°,就可以使用90°和180°这两组数据去做算法得到。运用Quad Binaural技术的话筒主要是3Dio的Omini,目前Oculus、Milk VR和Within这几个平台使用的就是这种格式。

3Dio Omni
Quad Binaural的优势在于采集了自然的HRTF信息,所以后期算法、解码都很简单。而且在水平角度上的声像定位比通常的低阶Ambsonic方式要好。但是这种方式缺点也很明显:由于4个方向的HRTF都在同一个水平面上,所以高度信息无法根据头部转动作出反馈。也就是说当你左右摇头的时候,声音会根据你的方向变化,而当你抬头或低头时,声音是没有变化的。
- Ambisonic
Ambisonic技术通过采集若干个声道的信息,经过运算去形成一个3D的全景声场。运用最为广泛的是使用4个声道的1阶Ambisonic(First Order Ambisonic,FOA)。
我们可以看到,这种Ambisonic话筒上有四个心形指向的振膜,指向左前LF、左后LB、右前RF、右后RB四个方向,这4个声道的信息叫做Ambisonic的A Format。通过4个声道的叠加或反相叠加,我们可以得到B-Format,如下图所示:
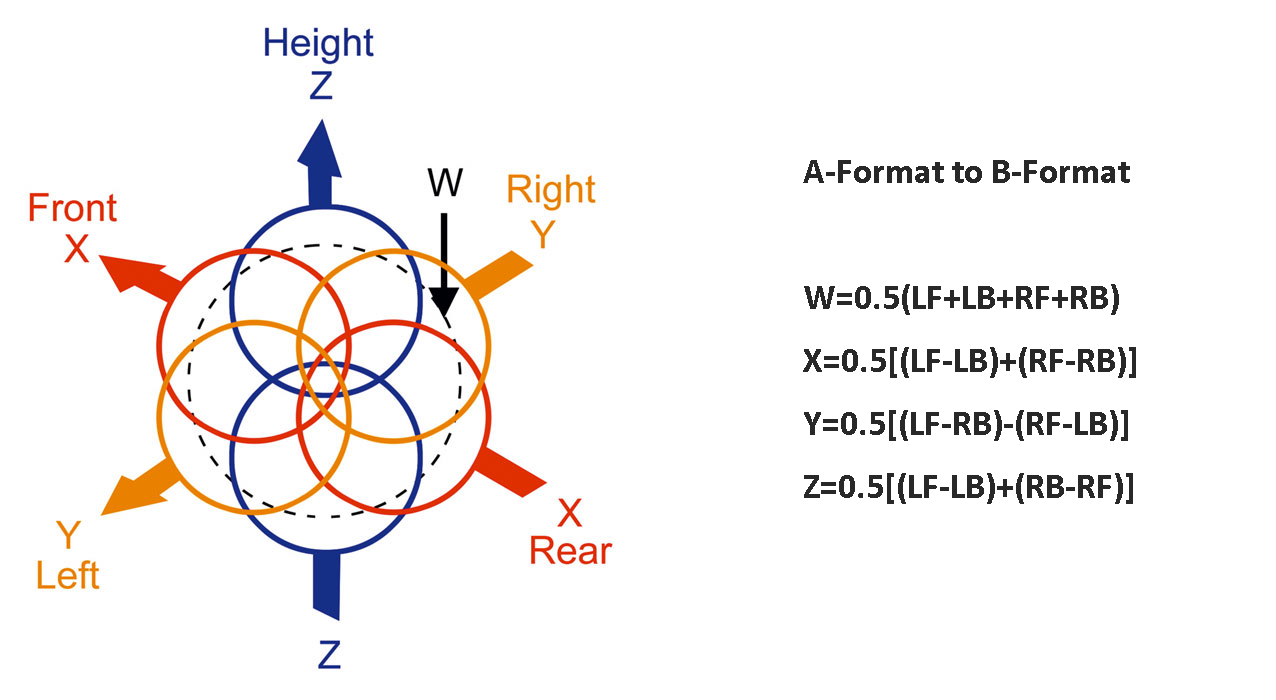
我们可以看出这样B-Format就拥有了X、Y、Z三个坐标的声音信息,可以去表征一个3D的声场了。Ambisonic B-Format实际上就是3个MS制式的组合,可以通过计算转换成Stereo、5.1 Surround、7.1 Surround甚至是更多的声道格式,当然通过引入HRTF也可以运用在Spatial Audio中。Google和Samsung GearVR采用的就是这种方式。

我们可以通过很多种产品来获得Ambisonic所需的4声道信息,这些产品价格相差也十分悬殊,今后有机会我们也会对这些产品进行一次全面的测评。

Ambisonic也有更高阶的版本(Higher Order Ambisonic,HOA)可以使用更多通道的声音来计算声场。比如VisiSonics的Audio Camera,就是用64通道的7阶Ambisonic技术。当然通道越多,声场的还原度就越高,计算也就越复杂。目前这样的高阶产品的应用还是以声学测量为主。

- Spatial Audio工具
| Oculus | FaceBook 360 | VisiSonics | Impulsonic | Noisemakers |
AAX | √ | √ |
|
| √ |
VST | √ | √ |
|
| √ |
Unity | √ |
| √ | √ |
|
Fmod | √ |
| √ | √ |
|
Wwise | √ |
| √ | √ |
|
目前已经有很多Spatial Audio的制作工具,可以让我们方便快捷的去进行VR音频的创作,基本上支持了所有的主流DAW和游戏音频引擎。下面让我们以Oculus Spatializer和FB360 Spatialworkstation为例,看一看这些工具的主要功能。

- 基本:增益 / 按距离衰减声压级设置
- 3D Panner:前后 / 左右 / 上下的声像位置
- Room Model:房间大小设置
- Room Model:房间6个墙面的反射系数
- 图形窗口切换:水平位置 / 垂直位置

- Input选择:Mono / MixDown / Ambisonic
- 3D Panner:水平角度
- 3D Panner:垂直角度
- 3D Panner:距离
- 3D Panner:扩散(声源的体积)
- 3D Panner:按距离衰减声压级
- Room model: 房间模型开关
- Room model: 房间大小
- Room model: 房间活跃度(反射系数)
- Room model: 房间效果的高频截止
我们可以看到,这些Spatial Audio工具基本有三个主要的功能:1、 3D Panner;2、 Room Model;3、 Ambisonic Decoder。有了这些实用的功能之后,我们就可以很方便的在DAW或者游戏音频引擎中去定位声源、创造声场和空间感。
Tips.1 目前的VR视频实际上仅仅是360度视频而已,我们只能在一个固定位置观看,谈不上交互,所以所有声源之间的相对位置都是固定的,一切声音也都基于时间线。而在VR游戏当中就要自由的多,我们可以随意在虚拟空间中移动,声源之间的相对位置也就会发生变化,也就是说游戏中的声音是完全基于对象的,这时我们就需要考虑到距离衰减、声源的指向性、物体对声源的遮挡等一系列的可能性。
Tips.2 在声音设计方面,不建议用3D的方式去处理操作界面音效和背景音乐,建议仍然使用Stereo方式去处理这个部分的声音。因为在你眼前的虚拟现实世界中,这两种声音都不是客观存在的,如果它定位在虚拟空间中而观众在视觉上又找不到声源,会有一种违和感。
Tips.3 你在3D Panner插件之前的效果处理,实际上都是在处理声源的原始声音而不是我们最终听到的声音,只有当这个声音从3D Panner里出来,才算是成为了我们听到的声音。这个在概念上与我们原先的混音有很大区别。而且3D Panner实际上是一个滤波器,对声音频率均衡上的影响很大,并且这种影响还会随方位而变化。所以建议做所有调整的时候都去监听3D Panner之后的信号。
Tips.4 如何去表现声源的体积感,这是一个比较棘手的问题。想想一个很大体积的声源,如果声音只是在很小的某一点发出的,这当然不真实。这时我们需要得到一个体积更大声音,Two Big Ears的工程师建议我们可以把同一个声音送到两个通道,一个通过使用3D Panner去处理,另一个则不用,以一定的比例去混合这两个信号,就可以得到一个定位清晰,并且有一定扩散感的声源。
Tips.5 当然在制作VR视频时,除了使用Quad-Binaural或者Ambisonic方式去录制,你也可以用音效库里的资源,加上3D Panner去制造一个简单的声场,然后将声场固化下来使用。因为VR视频中的声源位置是相对固定的。而在VR游戏中则完全不建议这样做,因为游戏中的3D定位完全基于对象,制造一个声场所需要的运算量很可能会把你的CPU拖垮。
Tips.6 早期反射声和混响,我们可以分开来看。对于声音的3D空间感这个属性,最重要的是来自早期反射声的作用。我们必须去使用上述的Room Model才能获得一个3D的早期反射声效果,但是混响是没有方向性的,所以我们可以将Room Model与传统的混响效果器配合起来使用,这样你就可以使用任意你喜欢的混响效果器了。但这里的一个前提是,在你的混响效果器中必须把早期反射声这个部分关掉,而且需要给混响加上30-60ms的Pre-Delay。
- Spatial Audio工具详细资料请查阅以下网页:
- Oculus Sptializer:https://developer3.oculus.com/documentation/audiosdk/latest/concepts/book-audio-intro/
- FaceBook 360 SpatialWorkstation:http://www.twobigears.com/spatworks/index.html
- VisiSonics RealSpace 3D:http://realspace3daudio.com/
- Impulsonic Phonon:https://www.impulsonic.com/
- Noisemakers Binauralizer:http://www.noisemakers.fr/
VR音频ABC这个系列文章到这里就告一段落了,今后我们会继续关注VR音频产业。将最新的行业与技术信息带给大家!
VR音频作为一个全新的声音领域,笔者也还在不断学习探索的过程当中,文中如有谬误还望不吝指教。另外如果各位对VR音频感兴趣,也欢迎交流讨论。
Email:Jinwei.Hsu@foxmail.com

转载文章请注明出自 Midifan.com
-
2019-02-10
 匿名
这他妈是什么破玩意
匿名
这他妈是什么破玩意 -
2018-12-10
匿名
回复 帛君:
-
2016-09-23
 帛君
感谢您漂亮的讲解! 但是我仍然对VR音频的制作充满了了疑惑,一个VR视频拿到手里,应该是一个展开的球形, 怎么在宿主里制作这段视频的音频呢?最后又以什么形式输出呢?观众的播放器又怎么定位呢...? 比如在左手边有个移动的车,那么我的头缓缓看向反方向,车声是有一些变化的,这个变化的过程是最后观看的时候才出现的,又怎么在成品前的后期中完成呢? 百思不得其解 再次感谢您的讲解,谢谢您~期待看到您其他的讲解。
帛君
感谢您漂亮的讲解! 但是我仍然对VR音频的制作充满了了疑惑,一个VR视频拿到手里,应该是一个展开的球形, 怎么在宿主里制作这段视频的音频呢?最后又以什么形式输出呢?观众的播放器又怎么定位呢...? 比如在左手边有个移动的车,那么我的头缓缓看向反方向,车声是有一些变化的,这个变化的过程是最后观看的时候才出现的,又怎么在成品前的后期中完成呢? 百思不得其解 再次感谢您的讲解,谢谢您~期待看到您其他的讲解。
